Machine learning

Artificial Intelligence (AI)
- The link between artificial intelligence (AI), machine learning and deep learning.
- Deep learning is a subset of machine learning, which is itself a subset of AI.
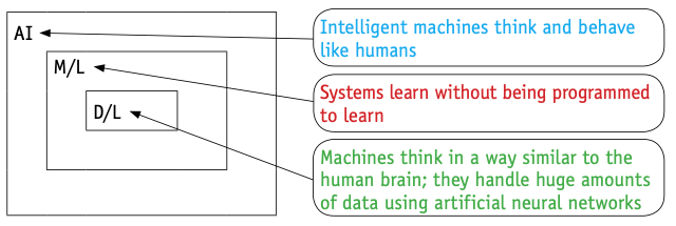
- AI can be thought of as a machine with cognitive abilities such as problem solving and learning from examples.
- All of these can be measured against human benchmarks such as reasoning, speech and sight.
- AI is often split into three categories.
- Narrow AI is when a machine has superior performance to a human when doing one specific task.
- General AI is when a machine is similar in its performance to a human in any intellectual task.
- StrongAI is when a machine has superior performance to a human in many tasks.
Examples of AI include
- news generation based on live news feeds (this will involve some form of human interaction)
- smart home devices (such as Amazon Alexa, Google Now, Apple Siri and Microsoft Cortana); again these all involve some form of human interaction
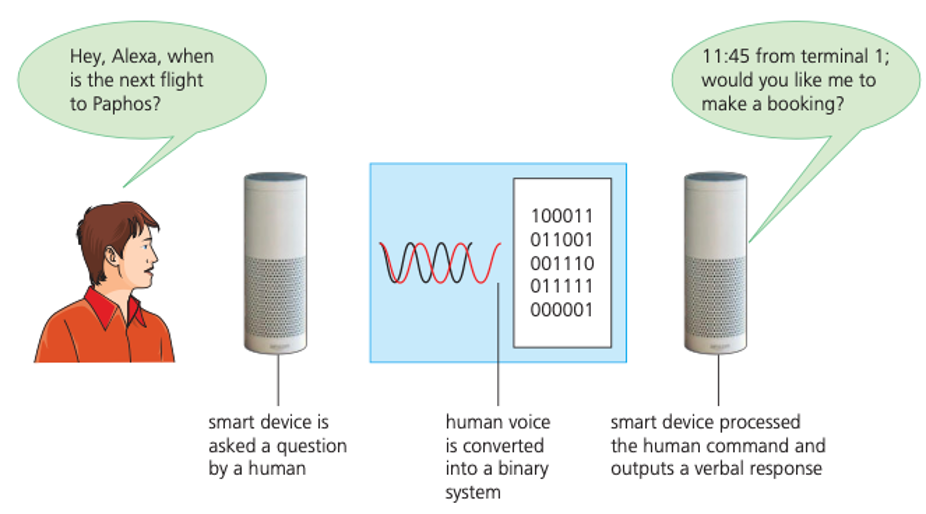
Machine learning
- Machine learning is a subset of AI, in which the algorithms are ‘trained’ and learn from their past experiences and examples.
- It is possible for the system to make predictions or even take decisions based on previous scenarios.
- They can offer fast and accurate outcomes due to very powerful processing capability.
- One of the key factors is the ability to manage and analyse considerable volumes of complex data – some of the tasks would take humans years, if they were to analyse the data using traditional computing processing methods.
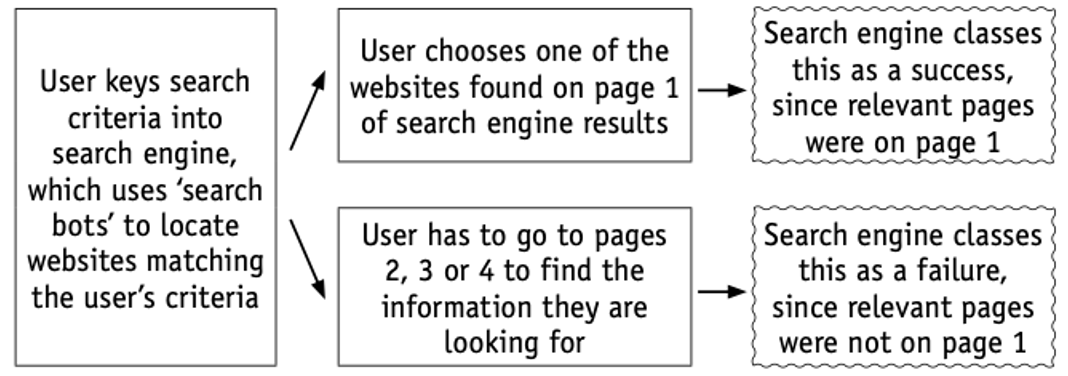
- A good example is a search engine:
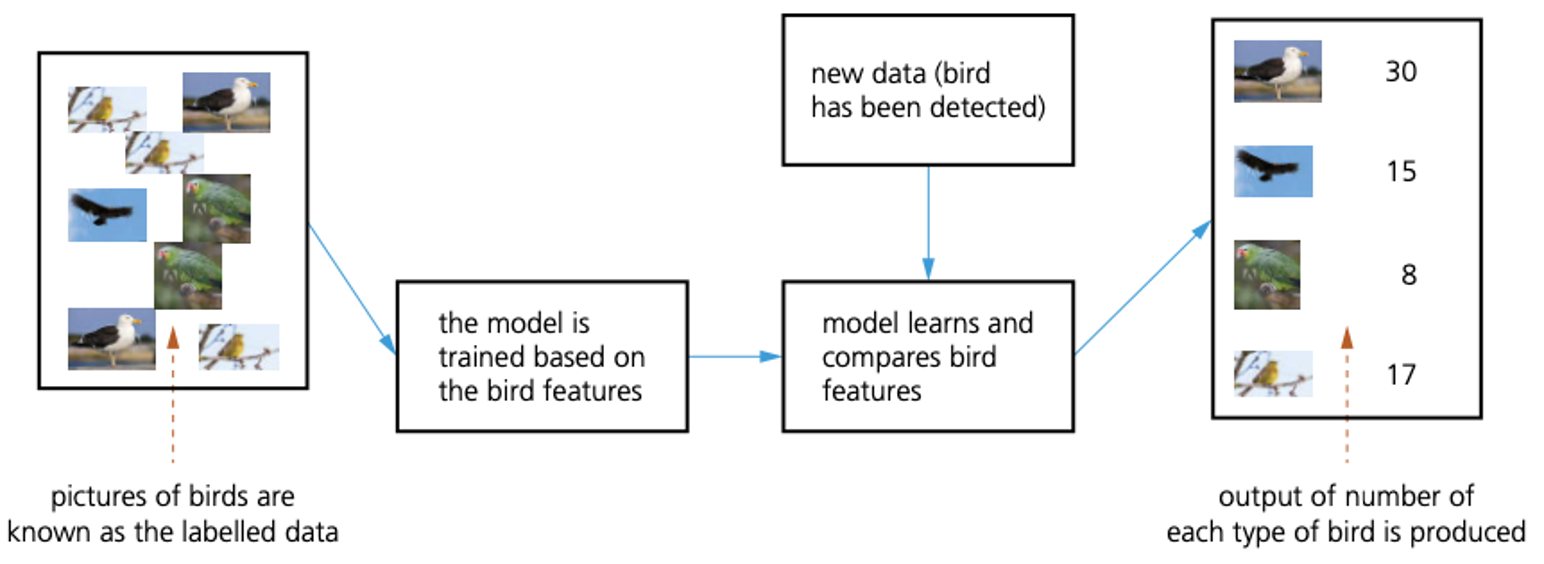
- The proposed system will consider bird features such as shape of beak, colour of feathers, body size, and so on.
- This requires the use of labelled data to allow the birds to be recognised by the system.
- There are a number of different types of machine learning, including:
- Supervised
- Unsupervised learning
- Reinforcement
- Semi-supervised (active)

Supervised learning
- Supervised learning makes use of regression analysis and classification analysis.
- It is used to predict future outcomes based on past data:
- The system requires both an input and an output to be given to the model so it can be trained.
- The model uses labelled data, so the desired output for a given input is known.
- Algorithms receive a set of inputs and the correct outputs to permit the learning process.
- Once trained, the model is run using labelled data.
- The results are compared with the expected output; if there are any errors, the model needs further refinement.
- The model is run with unlabelled data to predict the outcome.
- An example of supervised learning is categorising emails as relevant or spam/ junk without human intervention.
Unsupervised learning
- Systems are able to identify hidden patterns from the input data provided; they are not trained using the ‘right’ answer.
- By making data more readable and more organised, patterns, similarities and anomalies will become evident (unsupervised learning makes use of density estimation and k-mean clustering; in other words, it classifies unlabelled real data). Algorithms evaluate the data to find any hidden patterns or structures within the data set. An example is used in product marketing: a group of individuals with similar purchasing behaviour are regarded as a single unit for promotions.
Reinforcement learning
- The system is not trained.
- It learns on the basis of ‘reward and punishment’ when carrying out an action (in other words, it uses trial and error in algorithms to determine which action gives the highest/optimal outcome).
- This type of learning helps to increase the efficiency of the system by making use of optimisation techniques.
- Examples include search engines, online games and robotics.
Semi-supervised (active) learning
- Semi-supervised learning makes use of labelled and unlabelled data to train algorithms that can interactively query the source data and produce a desired output.
- It makes as much use of unlabelled data as possible (this is for cost reasons, since unlabelled data is less expensive than labelled data when carrying out data categorisation).
- A small amount of labelled data is used combined with large amounts of unlabelled data.
- Examples of uses include the classification of web pages into sport, science, leisure, finance, and so on.
- A web crawler is used to look at large amounts of unlabelled web pages, which is much cheaper than going through millions of web pages and manually annotating (labelling) them.
Deep learning
Deep learning structures algorithms in layers (input layer, output layer and hidden layer(s)) to create an artificial neural network that can learn and make intelligent decisions on its own.
Its artificial neural networks are based on the interconnections between neurons in the human brain.
The system is able to think like a human using these neural networks, and its performance improves with more data.
The hidden layers are where data from the input layer is processed into something which can be sent to the output layer. - Artificial neural networks are excellent at identifying patterns which would be too complex or time consuming for humans to carry out.
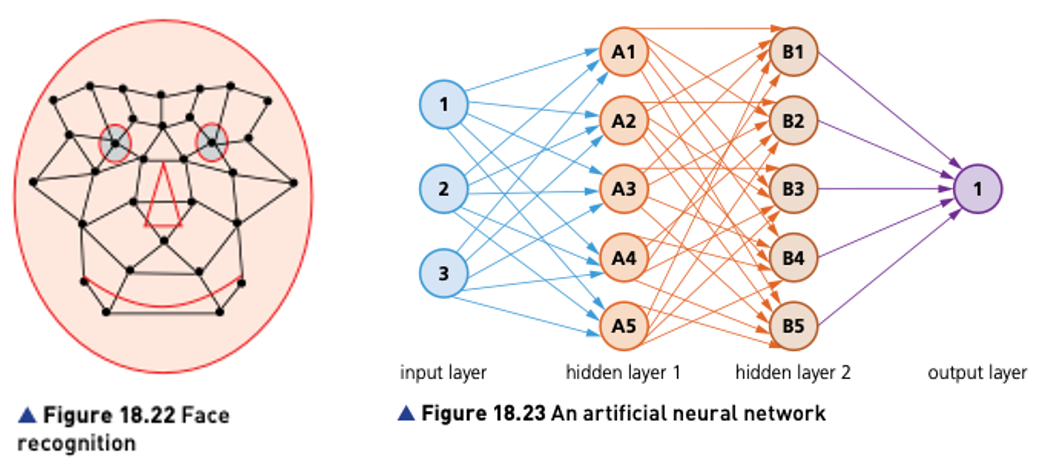
For example, they can be used in face recognition.
The face in Figure shows several of the positions used by the face recognition software.
Each position is checked when the software tries to compare two facial images.
A face is identified using data such as:
- distance between the eyes
- width of the nose
- shape of the cheek bones
- length of the jaw line
- shape of the eyebrows.
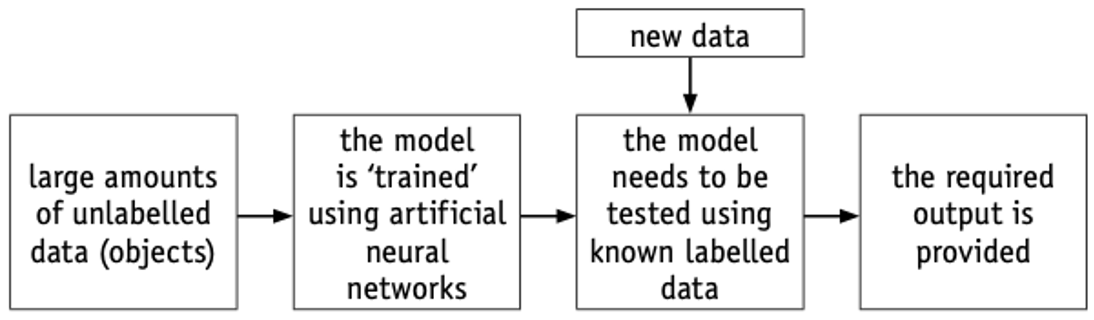
- Large amounts of unlabelled data (data which is undefined and needs to be recognised) is input into the model.
- One of the methods of object recognition, using pixel densities, was described above.
- Using artificial neural networks, each of the objects is identified by the system.
- Labelled data (data which has already been defined and is, therefore, recognised) is then entered into the model to make sure it gives the correct responses.
- If the output is not sufficiently accurate, the model is refined until it gives satisfactory results (known as back propagation – see Section 18.2.6).
- The refinement process may take several adjustments until it provides reliable and consistent outputs.
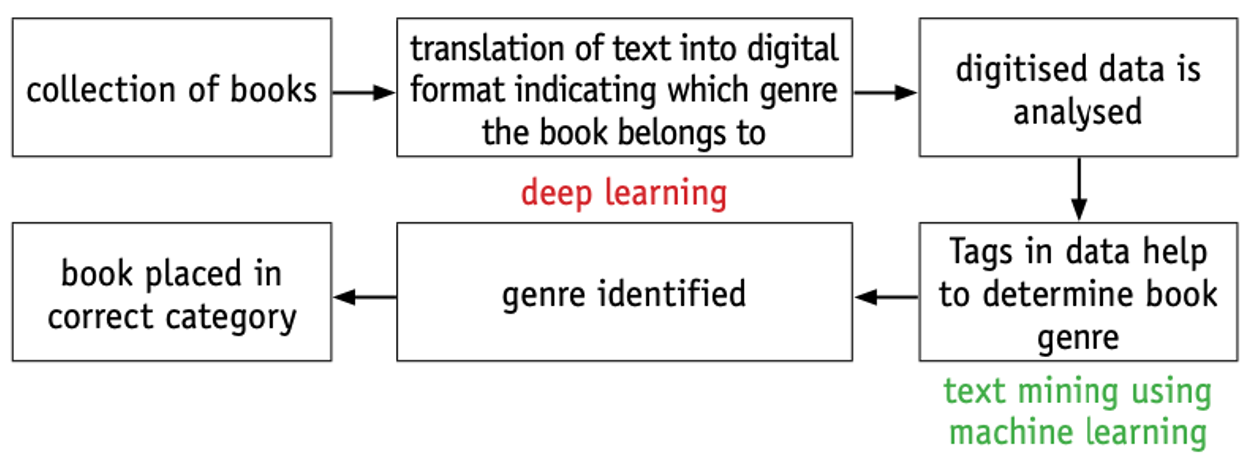
Text mining
- Suppose a warehouse contains hundreds of books.
- A system is being developed to translate the text from each book and determine which genre the book belongs to, such as a car engine repair manual.
- Each book could then be identified by the system and placed in its correct category.
- How could this be done using deep learning and machine learning techniques?
Machine learning and Deep learning
| machine learning | deep learning |
|---|---|
| enables machines to make decisions on their own basedon past data | enables machines to make decisions using an artificialneural network |
| needs only a small amount of data to carry out thetraining | the system needs large amounts of data during thetraining stages |
| most of the features in the data used need to beidentified in advance and then manually coded into thesystem | deep learning machine learns the features of the datafrom the data itself and it does not need to be identifiedin advance |
| a modular approach is taken to solve a given problem/task;each module is then combined to produce the final model | the problem is solved from beginning to end as a singleentity |
| testing of the system takes a long time to carry out | testing of the system takes much less time to carry out |
| there are clear rules which explain why each stage in themodel was made | since the system makes decisions based on its own logic,the reasoning behind those decisions may be very difficultto understand (they are often referred to as ablack box) |
What will happen in the future?
AI
- detection of crimes before they happen by looking at existing patterns
- development of humanoid AI machines which carry out human tasks (androids)
Machine learning
- increased efficiency in health care and diagnostics (for example, early detection of cancers, eye defects, and so on)
- better marketing techniques based on buying behaviours of target groups
Deep learning
- increased personalisation in various areas (such as individual cancer care which personalises treatment based on many factors)
- hyper intelligent personal assistants
Back propagation
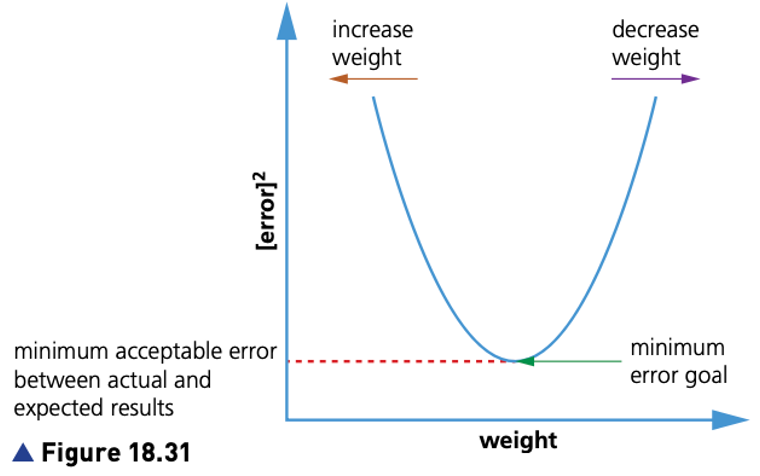
- When designing neural networks, it is necessary to give random weightings to each of the neural connections.
- However, the system designer will not initially know which weight factors to use to produce the best results.
- It is necessary to train the neural networks during the development stage

The training program is iterative; the outputs produced from the system are compared to the expected results and any differences in the two values/results are calculated.
These errors are propagated back into the neural network in order to update the initial network weightings.
This process (training) is repeated until the desired outputs are eventually obtained, or the errors in the outputs are within acceptable limits.
Here is a summary of the back propagation process:
- The initial outputs from the system are compared to the expected outputs and the system weightings are adjusted to minimise the difference between actual and expected results.
- Calculus is used to find the error gradient in the obtained outputs: the results are fed back into the neural networks and the weightings on each neuron are adjusted (note: this can be used in both supervised and unsupervised networks).
- Once the errors in the output have been eliminated (or reduced to acceptable limits) the neural network is functioning correctly and the model has been successfully set up.
- If the errors are still too large, the weightings are altered – the process continues until satisfactory outputs are produced.
There are two types of back propagation: static and recurrent:
- Static maps static inputs to a static output.
- Mapping is instantaneous in static, but this is not the case with recurrent.
- Training a network/model is more difficult with recurrent than with static.
- With recurrent, activation is fed forward until a fixed value is achieved.
Regression
- Machine learning builds heavily on statistics; for example, regression is one way of analysing data before it is input into a system or model.
- Regression is used to make predictions from given data by learning some relationship between the input and the output.
- It helps in the understanding of how the value of a dependent variable changes when the values of independent variables are also changed.
- This makes it a valuable tool in prediction applications, such as weather forecasting.
- In machine learning, this is used to predict the outcome of an event based on any relationship between variables obtained from input data and the hidden parameters.